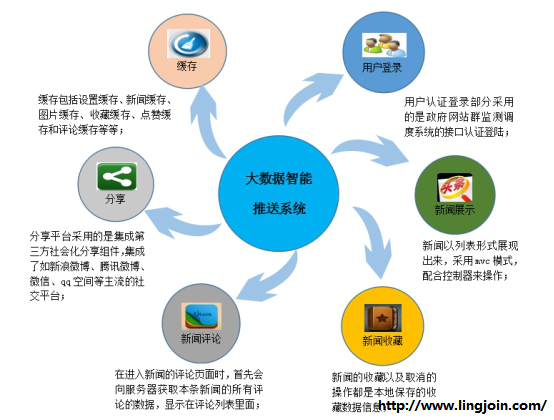
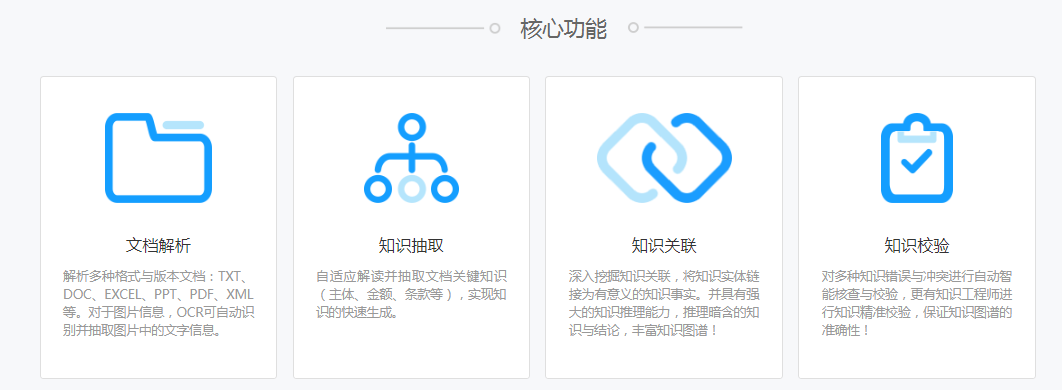
产品介绍
在当今信息爆炸的时代,伴随着社会事件和自然活动的大量产生(数据的海量增长),人类正面临着“被信息所淹没,但却饥渴于知识”的困境。随着计算机软硬件技术的快速发展、企业信息化水平的不断提高和数据库技术的日臻完善,人类积累的数据量正以指数方式增长。
数据挖掘是一个多学科领域,它融合了数据库技术、人工智能、机器学习、模式识别、模糊数学和数理统计等新技术的研究成果,可以用来支持商业智能应用和决策分析。例如顾客细分、交叉销售、欺诈检测、顾客流失分析、商品销量预测等等,目前广泛应用于银行、金融、医疗、工业、零售和电信等行业。数据挖掘技术的发展对于各行各业来说,都具有重要的现实意义。
数据挖掘技术具有以下特点:
1. 处理的数据规模十分庞大,达到GB、TB数量级,甚至更大。
2. 查询一般是决策制定者(用户)提出的即时随机查询,往往不能形成准确的查询要求,需要靠系统本身寻找其可能感兴趣的东西。
3. 在一些应用(如商业投资等)中,由于数据变化迅速,因此要求数据挖掘能快速做出相应反应以随时提供决策支持。
4. 数据挖掘中,规则的发现基于统计规律.因此,所发现的规则不必适用于所有数据,而是当达到某一临界值时,即认为有效.因此,利用数据挖掘技术可能会发现大量的规则。
5. 数据挖掘所发现的规则是动态的,它只反映了当前状态的数据库具有的规则,随着不断地向数据库中加入新数据,需要随时对其进行更新。
北京理工大学大数据搜索与挖掘实验室张华平主任研发的NLPIR大数据语义智能分析技术是满足大数据挖掘对语法、词法和语义的综合应用。NLPIR大数据语义智能分析平台是根据中文数据挖掘的综合需求,融合了网络采集、自然语言理解、文本挖掘和语义搜索的研究成果,并针对互联网内容处理的全技术链条的共享开发平台。
NLPIR大数据语义智能分析平台主要有采集、文档转化、新词发现、批量分词、语言统计、文本聚类、文本分类、摘要实体、智能过滤、情感分析、文档去重、全文检索、编码转换等十余项功能模块,平台提供了客户端工具,云服务与二次开发接口等多种产品使用形式。各个中间件API可以无缝地融合到客户的各类复杂应用系统之中,可兼容Windows,Linux, Android,Maemo5, FreeBSD等不同操作系统平台,可以供Java,Python,C,C#等各类开发语言使用。